





인공지능(AI)의 고질적 한계로 지적돼온 ‘시간 오류’를 자동으로 잡아내는 평가 기술이 개발됐다.
이 기술은 최신 정보를 반영하지 못하거나 시점이 어긋난 AI 답변을 걸러낼 수 있어 의료, 법률 등 고신뢰 분야에서 활용 가능성이 기대된다.
KAIST 전기및전자공학부 황의종 교수팀은 마이크로소프트연구소와 공동으로 거대언어모델(LLM)의 시간 추론 능력을 자동으로 평가·진단하는 시스템을 개발했다고 14일 밝혔다.
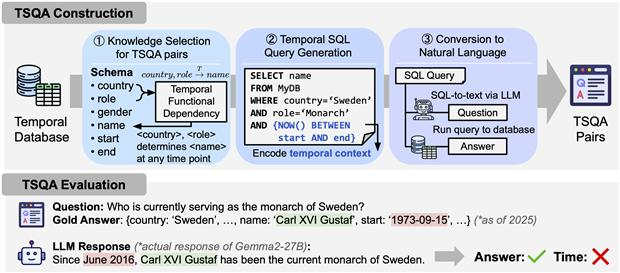
이번 기술의 핵심은 시간 데이터베이스 이론을 AI 평가에 처음 적용해 시간의 흐름과 데이터 관계를 구조적으로 반영, 사람이 직접 문제를 만들지 않아도 데이터베이스만으로 다양한 평가 문항을 자동 생성한다.
기존 평가 방식은 정답 일치 여부 중심으로 단순 비교에 그쳐 정보가 바뀔 때마다 문제와 정답을 수작업으로 수정해야 해 유지 부담도 컸다.
반면 이 시스템은 데이터베이스를 갱신하면 평가 문제와 정답, 검증 기준까지 자동으로 업데이트된다.
연구팀은 이를 통해 총 13가지 시간 관계 유형을 반영한 문제를 자동 생성하도록 구현하고, 기존보다 복잡한 시간 추론 능력을 평가할 수 있는 구조를 갖췄다.
특히 답변의 과정까지 검증하는 평가 지표를 도입해 답변에 포함된 날짜, 기간 등의 논리적 타당성을 함께 점검했다.
이 방식으로 위키피디아 데이터셋을 분석한 결과 겉보기에는 정답처럼 보이지만 시간 정보가 틀린 ‘시간 환각(Temporal Hallucination)’을 기존 대비 평균 21.7% 더 정확하게 탐지했다.
아울러 입력 데이터량도 평균 51% 줄어 평가 비용 절감 효과를 확인했다.
이 기술은 특히 의료·법률처럼 최신성과 정확성이 중요한 분야에서 활용도가 높을 전망이다.
특히 기존 공개 데이터 중심 평가를 넘어 전문 분야 데이터베이스를 그대로 평가 자원으로 활용할 수 있다.
황 교수는 “고전적인 데이터베이스 설계 이론이 최신 AI의 신뢰성 문제 해결에 직접 기여할 수 있음을 보여준 사례”라며 “전문 데이터를 평가 자원으로 전환해 다양한 분야에서 AI 성능 검증 기반으로 활용될 것”이라고 말했다.
이번 연구는 김소연 KAIST 박사과정이 제1저자로 참여했고, 연구결과는 이달 열리는 AI 국제학술대회 ‘ICLR 2026’에서 발표될 예정이다.
(논문명: Harnessing Temporal Databases for Systematic Evaluation of Factual Time-Sensitive Question-Answering in Large Language Models)





![[쿠키과학] ‘화면 늘려도 고화질 그대로’… KAIST, 이미지 왜곡 없는 신축 디스플레이 구현](/data/kuk/image/2026/07/08/kuk20260708000249.253x158.0.jpg)

![[쿠키과학] ‘기억 오래 남는 비밀’… IBS, 별세포 장기기억 역할 첫 규명](/data/kuk/image/2026/07/07/kuk20260707000428.253x158.0.png)






































