






천연물 항산화 연구의 가장 큰 걸림돌이었던 ‘비교 불가능성’을 해결할 표준 비교 체계가 나왔다.
한국한의학연구원(이하 한의학연) 김동선 책임연구원 연구팀은 서로 다른 실험법으로 얻은 항산화 데이터를 하나의 기준에서 해석할 수 있는 ‘이펙트 팩터(Effect Factor·EF)’ 프레임워크를 개발하고, 이를 바탕으로 586개 천연물 추출물 데이터베이스를 구축했다고 11일 밝혔다.
연구팀은 실험 방법과 단위가 다른 데이터를 같은 언어로 바꿔 비교하는 표준 인프라를 만드는 데 집중했다.
천연물 연구에서는 오래전부터 인삼과 녹차, 한약재 같은 다양한 소재의 항산화 기능을 측정했다.
하지만 연구 평가방법에 따라 활성산소를 얼마나 잘 제거하는지 보는 ABTS와 DPPH, 항산화 성분이 얼마나 들어 있는지 측정하는 총 폴리페놀 함량(TPC), 총 플라보노이드 함량(TFC)은 측정 원리와 단위가 모두 다르다.
같은 천연물을 연구했더라도 실험 조건이 다르면 결과를 직접 비교하기 어려웠고, 어떤 후보 물질이 상대적으로 유망한지 객관적으로 판단하기도 쉽지 않았다.
기존 연구들은 특정 소재가 높은 활성을 보였다는 결과를 제시하는 경우가 많았다.
하지만 서로 다른 연구 결과를 한데 모아 비교하거나 대규모 데이터베이스로 활용하기에는 한계가 있었다.

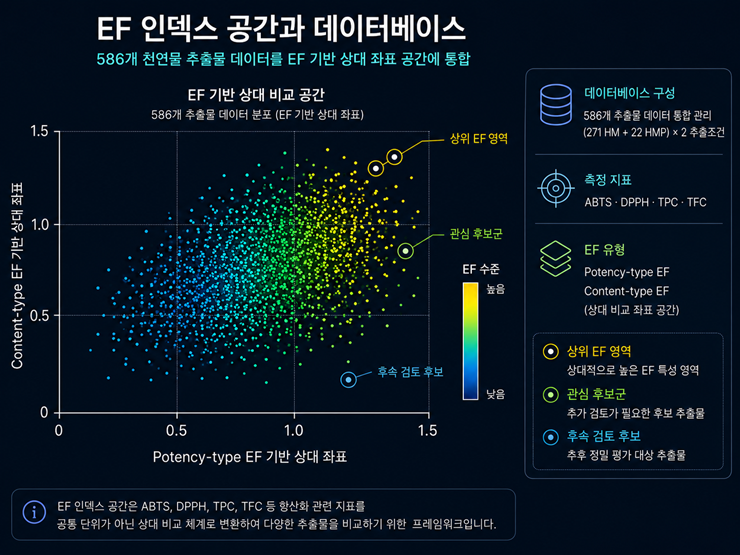
연구팀은 이런 문제를 해결하기 위해 항산화 관련 데이터를 EF라는 무단위 지수로 변환했다.
무단위 지수는 측정 단위를 없애 상대적인 위치와 특성만 비교하는 방식이다.
특히 연구팀은 각 실험의 의미를 유지하는 데 중점을 뒀다.
실제 활성산소 제거 능력을 평가하는 ABTS와 DPPH는 ‘포텐시 타입(Potency-type) EF‘로, 항산화 관련 성분의 양을 나타내는 TPC와 TFC는 ’콘텐트 타입(Content-type) EF‘로 구분했다.
성격이 다른 데이터를 하나의 점수로 합치지 않고 두 개의 축에서 비교하도록 설계했다.
또 500ppm 농도를 기준으로 단계별 희석 효과와 반응 지속성을 함께 반영하는 알고리즘을 적용했다.
낮은 농도에서도 항산화 효과가 유지되는 특성을 평가하고, 약한 신호가 실제보다 크게 해석되는 문제도 줄였다.
연구팀은 단일 한약재 271종과 한약 처방 22종을 물과 30% 에탄올로 추출해 모두 586개의 추출물 데이터를 확보했다.
이후 모든 데이터를 EF 기준으로 변환해 데이터베이스를 구축했다.
이 데이터베이스는 특정 약재의 우열을 결정하지 않고, 각 추출물을 항산화 반응성과 항산화 성분 함량이라는 두 개의 좌표축에 배치해 상대적인 특성을 비교하도록 만들었다.
이를 통해 연구자는 목적에 맞는 후보군을 빠르게 찾고, 추가 검증이 필요한 소재를 선별할 수 있다.
이번 연구는 건강기능식품과 기능성 화장품, 의약품 개발 과정에서 수많은 천연물 후보를 효율적으로 선별하고, 향후 축적하는 데이터를 활용해 항균과 항염, 면역조절 같은 다른 생리활성 연구로도 확장할 수 있다.
연구팀은 장기적으로 EF 데이터베이스가 인공지능 기반 한약 처방 연구의 핵심 자료가 될 것으로 기대하고 있다.
항산화와 항균, 항염, 면역조절 같은 다양한 기능 데이터를 함께 축적하면 질환 특성에 맞는 약재 조합을 데이터 기반으로 설계하는 연구도 가능하다.
김 책임연구원은 “이번 연구는 특정 소재의 우수성을 입증한 것이 아니라 586개 대규모 추출물 데이터를 동일한 기준으로 정리한 데이터베이스형 연구라는 점에서 차별성이 크다"며 ”EF 프레임워크는 다양한 항산화 데이터를 같은 기준으로 해석하는 비교 플랫폼으로, 천연물 데이터의 표준화와 후보 소재 탐색 연구의 중요한 기반이 될 것"이라고 말했다.
한편,이번 연구성과는 국제학술지 ‘애널리티카(Analytica)’에 게재됐다.
(논문명: A Standardized Comparative Index (Effect Factor) for Antioxidant Referencing and Database-Level Benchmarking of Complex Herbal Extracts)
이재형 기자 jh@kukinews.com







![[쿠키과학] 반도체 핵심 특수가스 ‘중수소 암모니아’ 국산화](/data/kuk/image/2026/06/11/kuk20260611000389.253x158.0.jpg)




































