KAIST가 소형 안테나로 벽 너머 인공지능(AI) 모델 구조를 탈취할 수 있는 새로운 보안 위협을 규명하고, 이를 막을 대응 기술을 공개해 화제다.
KAIST 전산학부 한준 교수팀은 싱가포르국립대(NUS) 및 저장대와 공동연구로 원거리 AI 모델 탈취 기술 ‘모델스파이(ModelSpy)’를 개발했다고 31일 밝혔다.
이 기술은 도청장치처럼 AI가 작동할 때 발생하는 미세신호를 포착해 내부 구조를 분석하는 게 특징이다.
연구팀은 AI 연산을 담당하는 GPU에서 발생하는 전자기파(EM)에 주목했다. AI가 복잡한 연산을 수행할 때 GPU 내부 활동에 따라 전자기파 신호 진폭이 특정 패턴으로 변조된다.
연구팀은 전자기파 신호와 GPU 내부 메모리 활동 사이 상관관계를 활용한 전이학습 기반 분석 기법을 설계해 모델 층 구성과 세부 설정값 ‘하이퍼파라미터’를 복원했다.
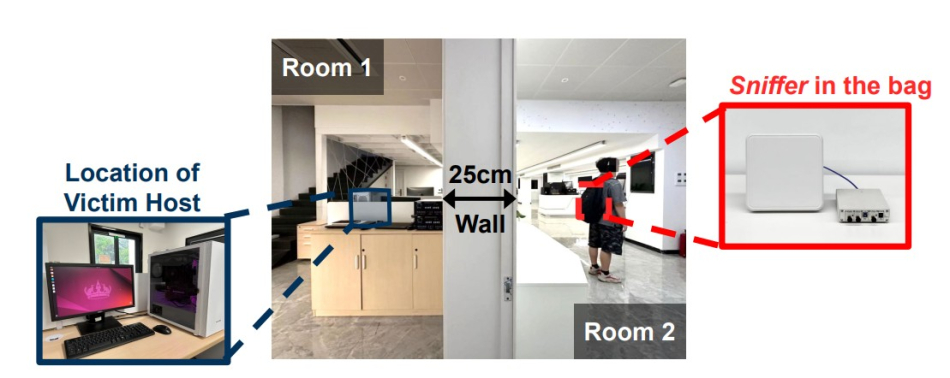
실험 결과 최신 GPU 5종을 대상으로 벽 너머 또는 최대 6m 거리에서 AI 모델 구조를 높은 정확도로 파악했다.
특히 딥러닝 모델 핵심 구조인 레이어(Layer)를 최대 97.6% 정확도로 추정했다.
이는 기존 해킹처럼 서버에 직접 침투하거나 악성코드를 설치할 필요 없이 가방에 넣을 수 있는 소형 안테나만으로 공격할 수 있어 심각한 보안 위협이 될 수 있다.
그동안 얼굴 인식이나 자율주행 등에 활용되는 딥러닝 모델구조는 내부를 알 수 없는 블랙박스 형태로 보호됐다.
하지만 모델 구조 정보가 유출되면 공격자가 이를 기반으로 정교한 적대적 공격을 수행할 수 있어 AI 보안에 치명적이다.
이에 연구팀은 이 같은 기술이 악용되는 상황을 막기 위해 전자기파 교란이나 연산 난독 등 대응 기술을 제시했다.
이를 통해 단순한 공격 시연 이상의 현실적인 방어 방안을 제안해 보안연구 사례로 인정받았다.
한 교수는 “이번 연구는 AI 시스템이 물리적 환경에서도 새로운 공격에 노출될 수 있음을 입증한 사례”라며 “자율주행이나 국가 기반 시설 같은 중요한 AI 인프라를 보호하기 위해 하드웨어와 소프트웨어를 아우르는 사이버-물리 보안체계 구축이 중요하다”고 설명했다.
한편, 이번 연구성과는 컴퓨터보안 최고 권위 학술대회 ‘NDSS 2026’에서 최우순 논문상을 수상했다.
(논문명: Peering Inside the Black-Box: Long-Range and Scalable Model Architecture Snooping via GPU Electromagnetic Side-Channel)





![박은식 산림청장, 산림 신품종 재배단지 방문 [쿠키포토]](/data/kuk/image/2026/06/05/kuk20260605000304.253x158.0.jpg)
![박은식 산림청장, 호우·강풍 대비 대책회의 [쿠키포토]](/data/kuk/image/2026/05/22/kuk20260522000340.253x158.0.jpg)
![박은식 산림청장, 봉하마을 방문… ‘소나무재선충병 대응 현장점검’ [쿠키포토]](/data/kuk/image/2026/05/21/kuk20260521000416.253x158.0.jpg)